
近年はNext.jsやAstroなど様々なフレームワークがWeb制作で活用されますが、その影響でJavaScriptの設計手法についても多様化しています。
同じ機能を開発する場合でも、フレームワークに依存した設計だったり、フレームワークに依存せず自身のルールで設計したり、また、これらを組み合わせてハイブリッド形式で設計したりと、様々な実装方法があります。
今回はWebサイト制作を主とするフロントエンドエンジニアが効率的に開発を進める上で、どのようにJavaScript設計を行うべきかを自身の経験に基づいて解説します。
補足事項
- プロジェクトの要件上、React、Vue、Angular、Svelteなどのメジャーなフレームワークを使用できない方を対象とした記事となります。
- 本記事では「クライアントサイドスクリプト」の設計手法についてご紹介します。
随所で「JavaScript」という表現を用いていますが、ミドルウェアやサーバーサイドの意味は含んでおりませんのでご留意ください。- 学術記事にも触れつつ解説しますが、プロジェクトの要件や個人の思想が影響している部分もありますので、「このような考え方もあるんだな」程度に捉えていただけますと幸いです。
JavaScript設計の課題
先ほども触れた通り、Web開発では様々なフレームワークを使用できます。
また、GitHub ActionsなどのCI/CDプラットフォームを活用することで、ソースコードの変更箇所の検知からサーバーへのアップロードまで自動化させることもできます。
こういった技術を用いることで、より効率的に開発を進められるようになった一方で、サイト制作における開発プロセスについては以下のような課題があると考えています。
1. プロジェクトによってはモダンな技術を使用できないケースがある
技術選定も最終的にはクライアントが求める要件に沿ったものでないといけません。
要件と聞くとデザインやサービスの機能(機能要件)に目が行きがちですが、「運用」や「保守性」なども顧客が求める要件(非機能要件)に含まれます。
個人的に技術選定をする上で最も影響度の大きい要件は「納品方法」だと考えています。
例えば、「静的ファイルをzip形式で納品」という要件の場合、以下のような条件を満たす必要があります。
- 納品ファイルを人が認識しやすい形式(ファイル名、ディレクトリなど)で出力する。
- 運用時は変更箇所のファイルのみが更新されるようにする。
そこまで複雑ではないのでは?と感じるかもしれませんが、例えばフレームワークにNuxt.jsを選定し、以下のようなファイルを作成したとします。
<template>
<p class="sample">Sample</p>
</template>
<script setup>
onMounted(() => {
console.log('Sample.vue mounted');
});
</script>
<style scoped>
.sample {
color: red;
}
</style>このファイルを静的ビルド(npm run generate)すると以下のようなファイルが出力されます。
(※nuxt.configがデフォルト設定の場合)
├── _nuxt/
│ └── index.e40911ba.css
│ └── index.e40911ba.js
│
├── index.html<!-- index.html -->
<p class="sample" data-v-e40911ba>Sample</p>
<!-- index.e40911ba.css -->
.sample[data-v-e40911ba] {
color: red;
}Nuxt.jsに限らずですが、マークアップ、スタイル、スクリプトを1つのファイルで記述できるフレームワークについては、一般的にビルド時にハッシュ値(e40911baの部分)が割り振られます。
これはブラウザにキャッシュが残っている状態でも変更内容が反映されるようにするための仕組みで、ビルド毎にランダムな値が生成されます。
仮にこのファイルを納品した後に、CSSに変更を加えたとしましょう。
変更箇所はCSSのみですが、マークアップとJavaScriptファイルに割り当てられるハッシュ値も変わってしまうため、htmlとjsファイルも合わせて納品する必要があります。
もちろんnuxt.configの設定などで調整できる部分もありますが、そもそもこれらのフレームワークはCI/CD開発の思想に沿ったものであり、これを静的出力に特化した設定に作り変えるというのは車輪の再発明にもなりかねません。
このように、特定のフレームワークにこだわるよりは、「HTML、CSS、JavaScriptをそれぞれ別々のモジュールとして管理し、Viteなどの汎用的なビルドツールを用いて各々のモジュールをバンドルする」といったレガシーな開発手法の方が適しているケースも多く存在しています。
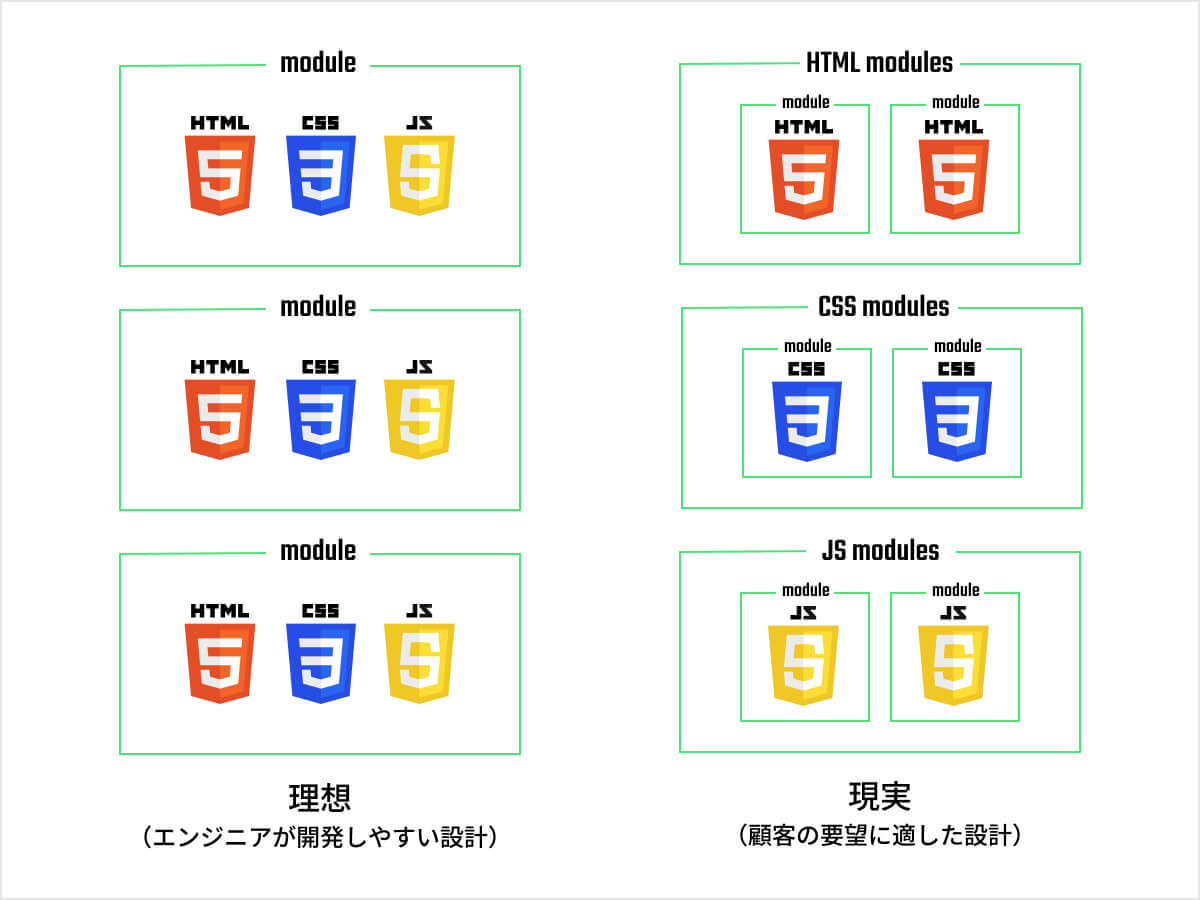
2. 個人に設計が委ねられ、ルールが多様化する
先ほど、JavaScriptの処理はJavaScriptモジュールとして管理するケースがあるという話をしました。
この環境においてもう1つ問題となるのが、フレームワークによる設計の縛りがなくなってしまうことです。
例えば、Nuxt.jsの場合だと、再利用可能なロジック(状態管理など)はcomposablesディレクトリに、アプリケーションの拡張(カスタムディレクティブなど)はpluginsディレクトリで管理するといったフレームワーク特有のルールがあります。
これらはチーム開発においてルールが共通化されるという点で大きなメリットとなっています。
フレームワークを使用しない場合、これらのルール管理は開発者自身に委ねられます。
JavaScriptにも「Atomic Design」や「Features Directory」など、CSSにおける「FLOCSS」のような設計思想は存在するものの、JavaScriptはCSSと比較してプロジェクトに応じて求められる機能が大きく変わるため、汎化の難易度が高い印象です。
結果、これらの設計思想をプロジェクトに落とし込めず、各々独自のルールが生まれてしまうという懸念があります。
ディレクトリ設計の例
理想のディレクトリ設計を検討する上で、まずは過去に僕自身が頭を悩ませながら作成したディレクトリ設計の例について見ていきます。
例1. すべてのモジュールをmodulesディレクトリで管理
scripts/
│
├── modules/ # モジュールの管理
│ ├── _top.js
│ └── _globalNav.js
│
├── main.js # modules配下のファイルを呼び出すモジュールをすべてmodules配下に格納し、main.jsをですべて呼び出すシンプルな方式です。
異なる技術要素を共存させるという点では、Features Directoryに近い考え方かもしれません。
メリット |
|
|---|---|
デメリット |
|
LPなど単一ページであればこれでも十分ですが、複数ページ実装ではモジュールの数が増えるため、次第に各々のモジュールがどの機能を保持しているのか判別が難しくなります。
また、モジュールを極力分割しないようにする影響で、1つのモジュールに対して複数の機能を詰め込む傾向にあり、些細なエラーでも影響範囲が大きく、連鎖的に他の機能が壊れてしまうというリスクも考えられます。
例2. 機能単位でディレクトリを細分化
scripts/
│
├── store/ # 状態管理
│ ├── _vars.js
│ ├── index.js
│
├── helper/ # ヘルパークラス(複雑かつ限定的な処理の補助)
│ ├── tabMenu.js
│ ├── modal.js
│
├── utility/ # ユーティリティクラス・関数(汎用的な処理の補助)
│ ├── debounce.js
│
├── pages/ # ページ単位の処理
│ ├── top/
│ └── _topTabMenu.js
│ └── index.js
│ ├── about/
│ └── _aboutModal.js
│ └── index.js
│ └── index.js
│
├── components/ # 共通コンポーネントの処理
│ ├── _globalNav.js
│ └── index.js
│
├── main.js # store、components、pagesの処理を呼び出す
機能単位でディレクトリを作成し、モジュールをグルーピングしていく方式です。helperやutilityといった命名はJava系統言語の「ヘルパークラス」「ユーティリティクラス」の概念を参考に、解釈を少しアレンジしたものになります。
store、helper、utilityといった小さな機能単位をもとに、最終的にはcomponentsやpagesといった大きな機能に落とし込んでいくため、AtomicDesignに近い設計思想となります。
メリット |
|
|---|---|
デメリット |
|
例1のデメリットを改善しつつ、ストアやスーパークラス、ユーティリティ関数などの共通化された小さな単位の処理を組み合わせることで、処理の重複がなく無駄の少ない開発が可能となります。
一方でディレクトリの階層が深くなることで、モジュールのインポート回数も増えるため、どこから参照された処理なのか判別が難しくなる上に、単純にimport文を何度も書くのが面倒であるという懸念もあります。
ディレクトリ設計の方向性
CSSの設計手法においても一般的に機能に応じて階層をもたせることが多いため、CSS側とルールを合わせるという点でも、例2のAtomicDesignをベースにした設計思想が方向性的には良さそうです。
あとは、この設計におけるデメリットを解消できないか検討してみます。
今回はJavaScriptフレームワークの1つであるAlpine.jsがどのような設計になっているか参考にみてみましょう。
まず、Alpine.jsを用いた処理の呼び出し方法について確認しておきます。
Alpine.storeで状態(どのモジュールからでも参照できる変数など)を登録Alpine.dataで処理(大きな単位の処理)を登録Alpine.startで登録した処理を実行
import Alpine from 'alpinejs'
// 1.storeの登録
Alpine.store('vars', {
headerHeight: 0,
init() {
const header = document.getElementById('header')
const setHeaderHeight = () => {
this.headerHeight = header ? header.clientHeight : 0
}
setHeaderHeight()
const resizeObserver = new ResizeObserver(() => {
setHeaderHeight()
})
resizeObserver.observe(header)
},
})
// 2.dataの登録
Alpine.data('test', () => ({
init() {
console.log(this.$store.vars.headerHeight)
},
destroy() {
console.log("Alpine.data('test') destroyed")
}
}))
// 3.登録された処理を実行
window.Alpine = Alpine
Alpine.start()呼び出し方法がわかったところで、次に実際のソースコードがどのような設計になっているか覗いてみます。(一部抜粋)
// alpine/packages/alpinejs/src/alpine.js
import { start } from './lifecycle'
import { data } from './datas'
import { store } from './store'
let Alpine = {
// 略
store,
start,
// 略
data,
}
export default AlpineAlpine.jsではAlpineという1つのオブジェクト(ルートオブジェクト)に対し、全ての処理を登録するよう設計されています。
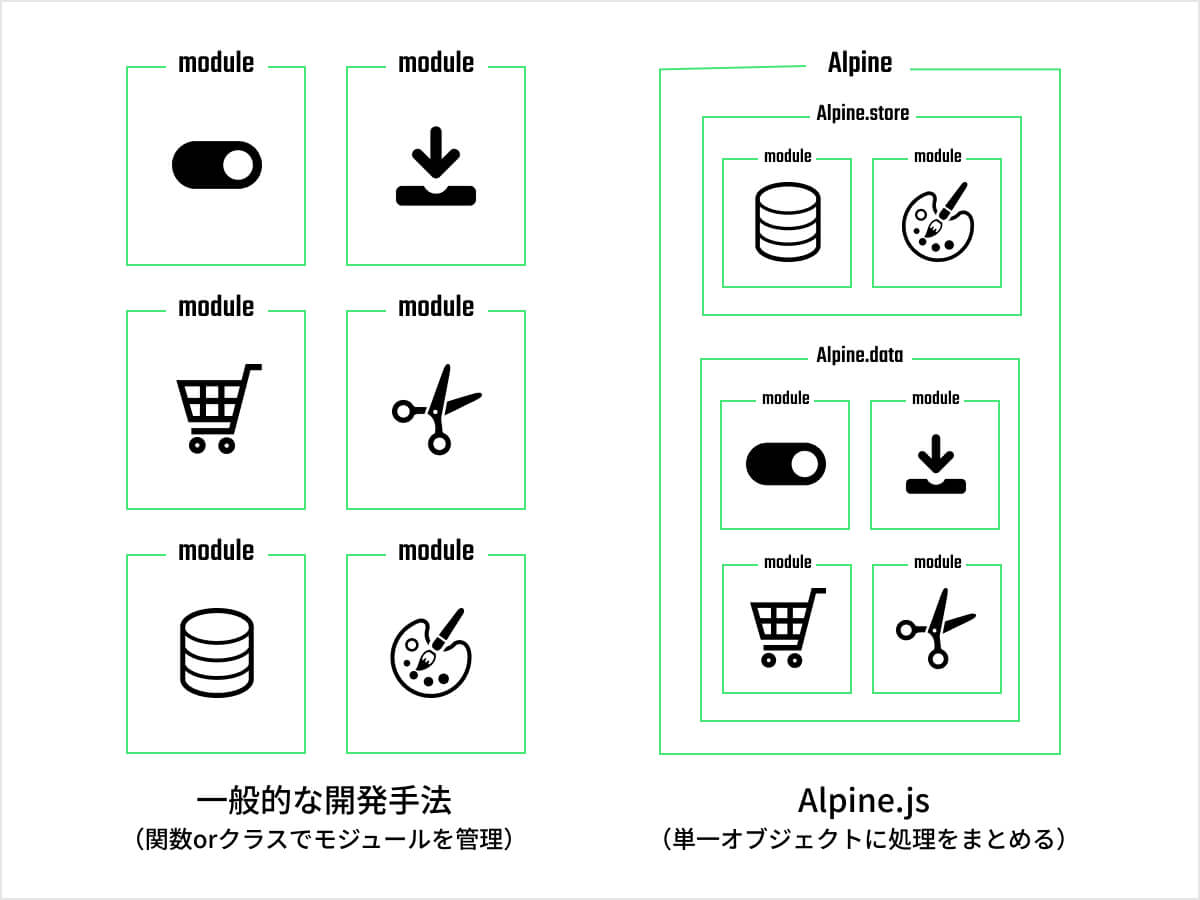
本来のモジュール開発は、関数やクラスを用いて並列で管理することがほとんどですが、単一オブジェクトに登録する形式により以下の恩恵を得ることができます。
1. モジュールを跨いで使用する変数を簡単に参照できる
this.$storeの部分から分かる通り、オブジェクト内部で処理を管理することで、オブジェクト内に存在する他の処理をthisキーワード経由で参照可能です。(※)
頻繁に使用する変数や関数を逐一インポートせずに済むため、モジュール参照の手間を省くことができます。
※TypeScriptによる型推論を使用する場合は
declare moduleによるalpinejsモジュールの型拡張が必要です。
2. ビルドツールの動的インポートと相性が良い
動的インポートとは、ワイルドカードのような書き方で複数のモジュールを一括でインポートする手法です(※)
例えばViteであれば以下のように記述します。
// scripts/components/index.js
import.meta.glob('./*.{js}', { eager: true }) // components配下のモジュールを一括で読み込む
// scripts/main.js
import './components'; // 即時実行でOK関数やクラスを動的インポートを用いて実行させる場合は少し複雑な処理が必要ですが、オブジェクトに登録する形式であれば、モジュールの中身をそのまま参照(eager: true )しつつ、import文の即時実行機能を用いて簡単に対応できます。
なお、この時点では処理を登録しているだけで、処理の実行(Alpine.start())は任意のタイミングで設定できる点も大きな強みです。
※TypeScriptの観点で型安全的に問題ないのかと言われるとNoですが、Alpine.jsでは
Alpine.dataを呼び出す際にマークアップ上で指定することから、どちらにせよ型チェックが効かないため、このあたりは堅牢性より開発効率を優先したほうが良いと考えています。
3. モジュールの実行タイミング(初期化・破棄)をまとめて管理できる
Alpine.jsはDOMの監視機能が備えられており、クライアントサイドで動的にコンテンツを更新した際(Ajaxなど)も、追加・削除されたコンテンツに対し、都度初期化or破棄の処理を実行できます。
const insert = () => {
const insertButton = document.getElementById('insert-button');
insertButton.addEventListener('click', () => {
insertButton.innerHTML = `<div x-data="alert"></div>`
})
}
const remove = () => {
const removeButton = document.getElementById('remove-button');
removeButton.addEventListener('click', () => {
const alertComponent = document.querySelector('[x-data="alert"]')
if (alertComponent) {
alertComponent.remove();
}
})
}
insert();
remove();
// ページ読み込み時にDOM上に該当要素が存在しないためログは出力されない
const alert = () => {
const alertComponent = document.querySelector('[x-data="alert"]');
if (alertComponent) {
console.log('Alert component initialized')
}
}
alert();
// ページ読み込み後に動的に追加・削除された要素に対してもログが出力される
Alpine.data("alert", () => ({
init() {
console.log("Alert component initialized");
},
destroy() {
console.log("Alert component destroyed");
}
}))通常、scriptファイルはページ読み込み時に評価されるため、動的に追加された要素に対して処理を発火させるには工夫が必要です。
Alpine.jsでは式の評価後もDOMを監視し続けているため、こういった処理に対しても柔軟に対応することができます。
察しの良い方はお気づきかもしれませんが、この機能はAlpineオブジェクトの内部にMutationObserverを設置することで実現されています。
モジュールをクラスや関数で管理する場合、各々のモジュールにMutationObserverを設置するといった対応になりますが、Alpine.jsは単一オブジェクトに処理がまとめられているため、登録された処理を一括で監視するシステムを構築できています。
ディレクトリ設計の改善
Alpine.jsの設計から学んだ内容を、先程の構成に落とし込んでみます。
scripts/
│
├── core/ # ルートオブジェクトの定義 ←追加
│ ├── app.js
│
├── store/ # 状態管理
│
├── helper/ # ヘルパークラス(複雑かつ限定的な処理の補助)
│
├── utility/ # ユーティリティクラス・関数(汎用的な処理の補助)
│
├── pages/ # ページ単位の処理
│
├── components/ # 共通コンポーネントの処理
│
├── main.js # store、components、pagesの処理を呼び出す// core/app.js
class App {
#storeList = {}
#storeInstance = {}
#dataList = {}
#dataInstance = new Map()
#dataAttribute = 'data-app'
#appObserver = null
/**
* Appクラスを初期化するメソッド
* 初期化後に'app:init'イベントを発火
* @returns {Promise<App>} - Appインスタンスを返す
* @throws - 初期化に失敗した場合はエラーを投げる
*/
async start() {
try {
await this.#initStore()
this.#appObserver = this.#observeData()
document.dispatchEvent(
new CustomEvent('app:init', {
bubbles: true,
composed: true,
cancelable: true,
}),
)
return this
} catch (error) {
console.error('Failed to start app:', error)
throw null
}
}
/**
* Store(状態管理)の登録を行うメソッド
* @param {string} name - Storeの名前を記述
* @param {Object} callback - Storeに定義するオブジェクトを記述
* @throws - Storeの名前が重複している場合はエラーを投げる
* @returns {App} - Appインスタンスを返す
*/
store(name, callback) {
if (this.#storeList[name]) {
throw new Error(`Store "${name}" is already registered.`)
}
this.#storeList[name] = callback
return this
}
/**
* Data(一般的な処理)の登録を行うメソッド
* @param {string} name - Dataの名前を記述
* @param {Function} callback - Dataに定義するオブジェクトを関数で記述
* @throws - Dataの名前が重複している場合はエラーを投げる
* @returns {App} - Appインスタンスを返す
*/
data(name, callback) {
if (this.#dataList[name]) {
throw new Error(`Data "${name}" is already registered.`)
}
this.#dataList[name] = callback
return this
}
async #initStore() {
try {
for (const [name, definition] of Object.entries(this.#storeList)) {
this.#storeInstance[name] = { ...definition }
}
for (const [name, instance] of Object.entries(this.#storeInstance)) {
if (typeof instance.init === 'function') {
await instance.init.call(instance)
}
}
} catch (error) {
console.error('Failed to initialize store:', error)
throw null
}
}
async #initData(domElement, dataName) {
try {
if (!this.#dataList[dataName]) {
console.error(`Data "${dataName}" not found`)
return null
}
const data = this.#dataList[dataName]()
data.$store = this.#storeInstance
data.$el = domElement
this.#dataInstance.set(domElement, {
name: dataName,
instance: data,
})
if (typeof data.init === 'function') {
await data.init.call(data)
}
return data
} catch (error) {
console.error(`Failed to initialize data "${dataName}":`, error)
throw null
}
}
#destroyData(domElement) {
const data = this.#dataInstance.get(domElement)
if (!data) return
if (typeof data.instance.destroy === 'function') {
data.instance.destroy.call(data.instance)
}
this.#dataInstance.delete(domElement)
}
// DOM監視
#observeData() {
const registerData = (els) => {
for (const el of els) {
if (!this.#dataInstance.has(el)) {
const dataName = el.getAttribute(this.#dataAttribute)
if (dataName) {
this.#initData(el, dataName)
} else {
console.warn(`Empty app data name for element:`, el)
}
}
}
}
const observer = new MutationObserver((mutations) => {
for (const mutation of mutations) {
for (const node of mutation.addedNodes) {
if (!(node instanceof HTMLElement)) continue
const elements = [
...(node.hasAttribute(this.#dataAttribute) ? [node] : []),
...node.querySelectorAll(`[${this.#dataAttribute}]`),
]
registerData(elements)
}
for (const node of mutation.removedNodes) {
if (!(node instanceof HTMLElement)) continue
if (this.#dataInstance.has(node)) {
this.#destroyData(node)
}
const elements = node.querySelectorAll(`[${this.#dataAttribute}]`)
for (const el of elements) {
if (this.#dataInstance.has(el)) {
this.#destroyData(el)
}
}
}
}
})
observer.observe(document.body, {
childList: true,
subtree: true,
attributes: true,
attributeFilter: [this.#dataAttribute],
})
registerData(document.querySelectorAll(`[${this.#dataAttribute}]`))
return observer
}
}
export default new App()ベースの考え方はAlpineリスペクトですが、プロパティやメソッドのカプセル化を実現するためにクラス構文を使用しています。
処理の呼び出し方法はAlpineと同様、Appインスタンスに対し、store/の処理はstoreメソッドを、components/やpages/の処理はdataメソッドを用いて処理を登録していきます。dataメソッドを通して登録した処理は、マークアップ上でdata-app="データ名"の形式でdata属性を追加することで呼び出されます。
また、helper/とutility/はAppインスタンスには登録せず、store/、components/、pages/の構築を補助するクラス・関数を格納し、従来通りimport文で処理を呼び出します。
これらはインスタンス化や引数の設定など、より高度なルールに基づいて処理を呼び出す必要があるため、TypeScriptによる型推論をスムーズにするためにもこのような仕様にしています。
なお、Appインスタンスにはstore、data、startメソッドと、DOMの監視機能のみを搭載しており、ディレクティブ機能などは外しています。
Alpine.jsと比較すると簡易的な構成にはなりますが、改善前のディレクトリ設計と比較して、動的インポートやthisキーワードを用いた変数の参照が可能となるため、手間を削減しつつも破綻しづらいテンプレートとして、理想に近い構成になったのではないかと思います。
困った時はAlpine.jsに頼る
今回はプレーンなJavaScriptによる設計手法をご紹介しましたが、もちろん先程ご紹介したAlpine.jsをそのまま使用するのもアリだと思います。
フレームワークに頼ることなく自作で何とかしているのを見ると確かにカッコイイです。
が、冒頭でも述べた通り、何でもスクラッチでやろうとすると、どうしても独自のルールが生まれてしまい、丁寧に設計しないとチーム開発においては障害になってしまう可能性があります。
また、フレームワークを使うことによる発見もたくさんあります。
僕自身もディレクトリ設計に悩む中でAlpine.jsを知り、実際に使用してみることでルートオブジェクトに統合する、という新しい考え方に触れることができました。
jQueryの名残からか、フレームワークに依存した書き方に頼るのはどうなのか?といったネガティブなイメージもあるかもしれませんが、少しでも気になった方は一度触ってみることをオススメします!


